Frequently Asked Questions
Product Information
What is THRON PLATFORM and what does it do?
THRON PLATFORM is a SaaS solution that unifies Digital Asset Management (DAM), Product Information Management (PIM), and Content Delivery Network (CDN) functionalities into a single platform. It enables businesses to centralize, manage, and distribute photos, videos, documents, and product data, streamlining workflows and reducing IT costs by eliminating the need for multiple tools and integrations. [Source]
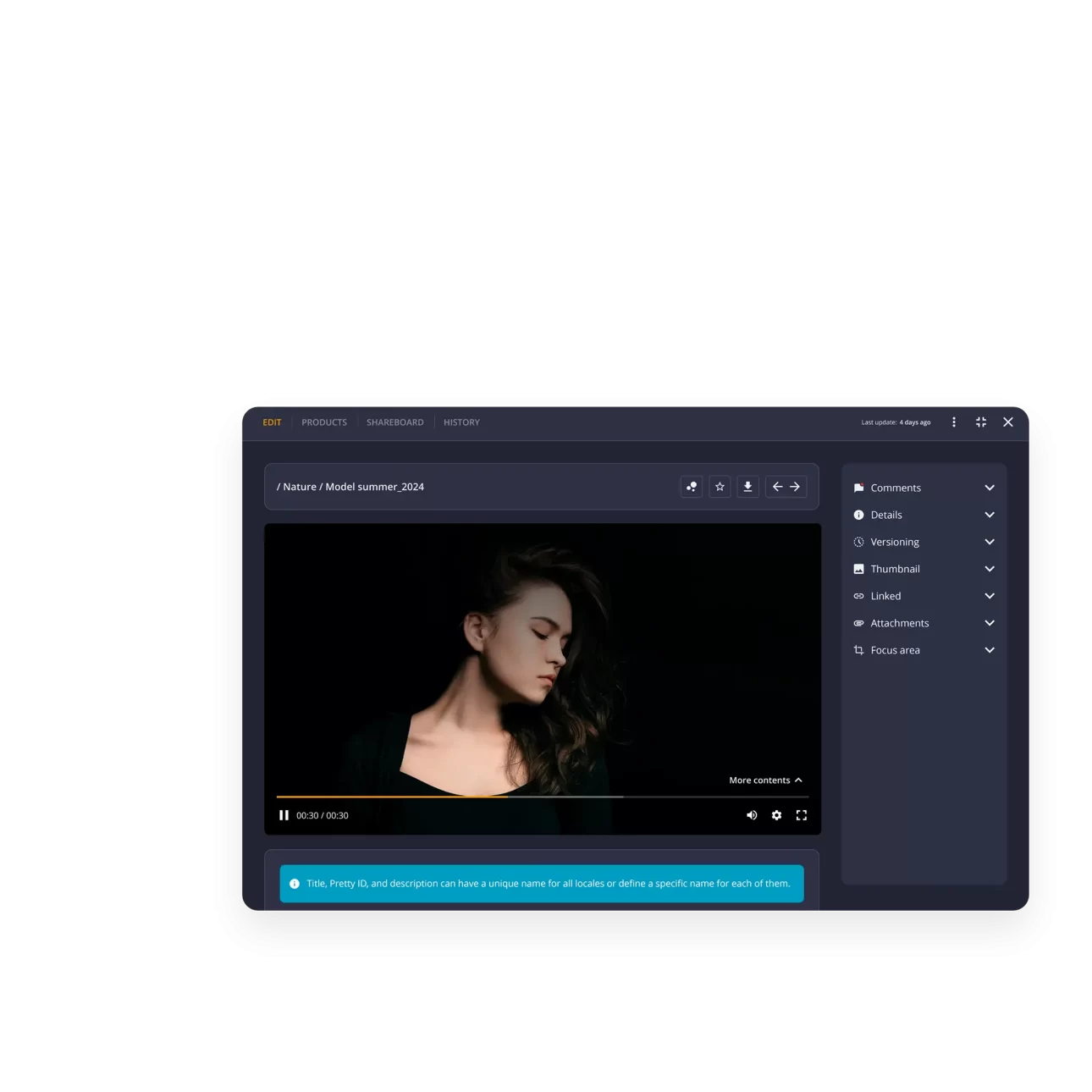
What are the main areas of the THRON PLATFORM?
The main areas of THRON PLATFORM are:
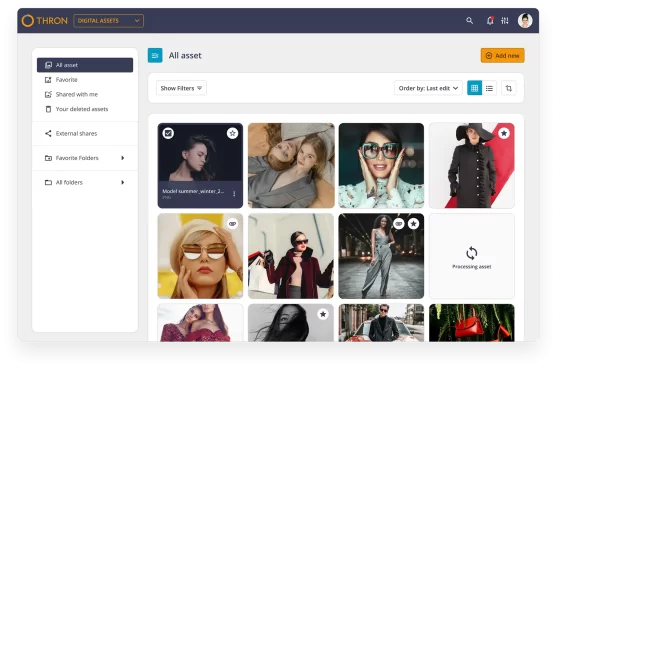
- Digital Assets Area: Organize and manage all digital assets in any format, supporting creative and approval flows.
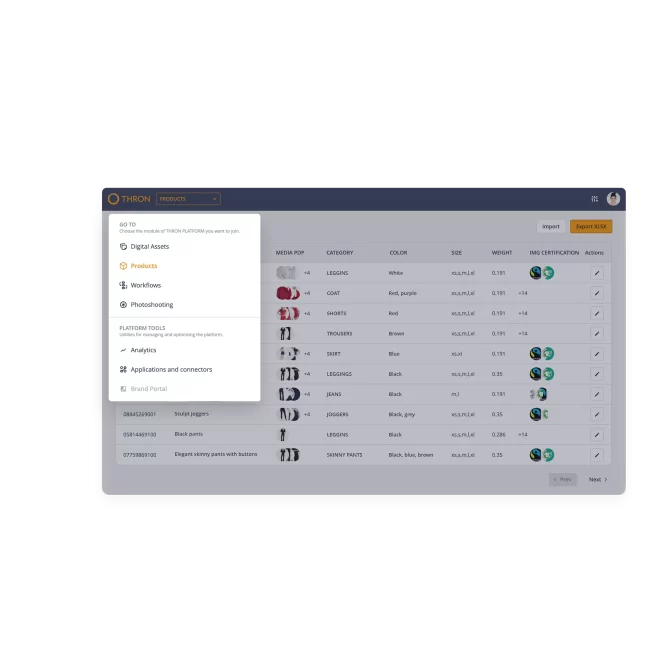
- Products Area: Manage product information and digital media together, enabling real-time updates and AI-generated multilingual descriptions.
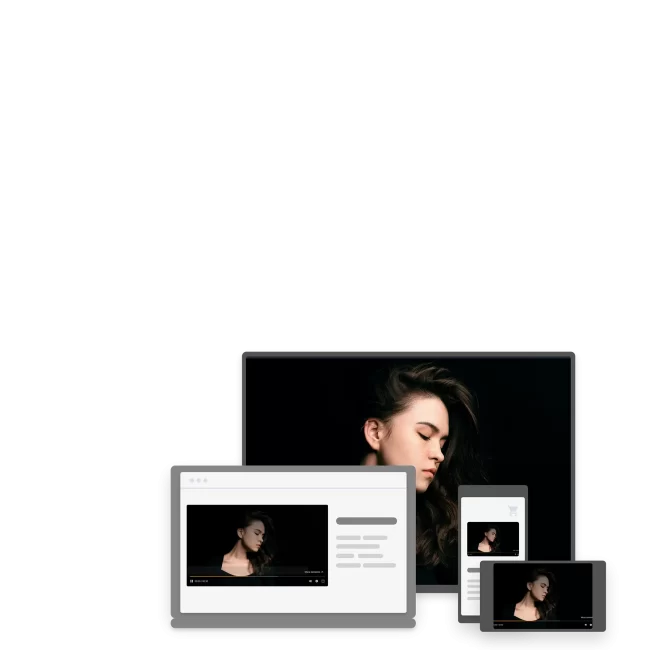
- AI MediaBoost Area: Optimize content performance on every touchpoint, ensuring fast, high-quality delivery across websites, e-commerce, and marketplaces.
[Source] How does THRON PLATFORM help with digital asset management?
THRON PLATFORM provides a native SaaS DAM solution that allows you to organize all digital assets, instantly find what you need, and streamline creative and approval workflows. It eliminates data duplication and leverages AI for classification and categorization. [Source]
What is the Product Information Management (PIM) area in THRON?
The PIM area in THRON PLATFORM enables you to manage product information and digital media together on a single platform. It supports real-time variant management and uses AI to generate engaging, multilingual product descriptions automatically. [Source]
How does the AI MediaBoost area enhance content delivery?
The AI MediaBoost area optimizes content for every touchpoint by publishing, retrieving, and updating assets directly from the DAM. It uses AI to balance loading speed and visual quality, automatically selecting the ideal format and resolution for each context. [Source]
What is the unified data model in THRON PLATFORM?
THRON PLATFORM uses a unified data structure for DAM and PIM, ensuring all teams are aligned and minimizing errors or miscommunication across departments, systems, and channels. [Source]
How does THRON PLATFORM support collaboration?
THRON PLATFORM enables effortless collaboration by allowing teams to approve, review, comment, and exchange feedback in an agile way. It supports the design of digital workflows without code, making it easy for teams to work together and leverage each other's contributions. [Source]
What is the Share Board & Access feature?
The Share Board & Access feature allows you to share or revoke assets across channels, apps, and users instantly. Real-time content access automatically verifies permissions, providing easy and secure control over digital assets. [Source]
How does THRON PLATFORM handle content intelligence and monitoring?
THRON PLATFORM collects performance data for your assets, enabling data-driven strategies to optimize information asset management. Monitoring dashboards provide insights into the volume and quality of digital asset usage. [Source]
What are the platform specifications of THRON?
THRON is a SaaS, cloud-native platform with flexible architecture and technology that guarantees consistently high performance, regardless of traffic load. It is designed for worldwide, elastic scalability. [Source]
Features & Capabilities
What are the key features of THRON PLATFORM?
Key features include unified DAM and PIM, AI-powered automation, centralized repository, omnichannel delivery, content intelligence, seamless integrations, robust security, and a customer success program. These features help automate workflows, ensure brand consistency, and improve operational efficiency. [Source]
Does THRON PLATFORM support automation and workflow design?
Yes, THRON PLATFORM supports automation of content approval, distribution, and optimization processes. It also allows users to design digital workflows without writing code, making it easy to streamline and automate complex processes. [Source]
How does THRON PLATFORM ensure brand consistency?
THRON PLATFORM provides a single source of truth for all assets and data, ensuring consistent communication across all channels. Automated asset delivery and centralized management help maintain brand consistency and reduce the risk of errors. [Source]
What integrations does THRON PLATFORM offer?
THRON PLATFORM offers modern APIs and certified connectors for popular platforms such as AEM, Magento, Shopify, Drupal, WordPress, and Salesforce Commerce Cloud. It also integrates with ERP, creative suites like Adobe CC, IT security tools, and user experience tools. [Source]
Does THRON PLATFORM provide APIs?
Yes, THRON PLATFORM provides modern, robust, and easy-to-implement APIs that allow integration with any system or endpoint, ensuring secure and high-performance communication. [Source]
What technical documentation is available for THRON PLATFORM?
THRON offers detailed technical documentation, including platform architecture, security, and data management. Resources include downloadable infographics, white papers, and comprehensive documents for IT and digital leaders. [Architecture White Paper] [Security & Data Management]
How does THRON PLATFORM support omnichannel content delivery?
THRON PLATFORM automates asset delivery across all channels, ensuring content is always up-to-date and consistent. Its omnichannel capability improves user experience and increases conversions by optimizing content for every touchpoint in real time. [Source]
What is the Customer Success Program?
The Customer Success Program pairs each customer with a specialist who provides customized onboarding, training, proactive monitoring, and consultancy to ensure optimal use of the platform. The program has received 100% positive feedback. [Source]
Security & Compliance
What security certifications does THRON PLATFORM have?
THRON PLATFORM is certified with ISO 27001:2022 (information security management), ISO 9001:2015 (process quality), ISO 27017:2015 (cloud service security controls), and ISO 27018:2019 (personal data protection in virtualized environments). It is also fully GDPR compliant. [Source]
How does THRON PLATFORM ensure data security and privacy?
THRON follows OWASP principles for secure development, uses infrastructure as code for server management, and employs advanced XDR systems for threat detection. Data is encrypted, replicated across AWS data centers, and distributed via HTTPS. [Source]
Is THRON PLATFORM GDPR compliant?
Yes, THRON PLATFORM is fully compliant with the General Data Protection Regulation (GDPR), ensuring data protection and privacy for all users. [Source]
What infrastructure does THRON PLATFORM use for hosting and security?
THRON PLATFORM is hosted on Amazon Web Services (AWS), leveraging secure data centers, DDoS protection, automatic scaling, and data replication across multiple centers to ensure availability and integrity. [Source]
Use Cases & Benefits
Who can benefit from using THRON PLATFORM?
THRON PLATFORM is ideal for marketing, e-commerce, operations, digital/CIO, and IT teams across industries such as fashion, ceramics, beauty & pharma, sporting goods, manufacturing, interior design, retail, and automotive. [Source]
What business impact can customers expect from THRON PLATFORM?
Customers can expect measurable benefits such as 90% time savings in asset search, 50% reallocated time to strategic activities, 99.9% service availability, and up to 317% ROI with a payback period of less than 6 months (Forrester TEI study). [TEI Report]
What problems does THRON PLATFORM solve?
THRON PLATFORM addresses challenges such as excessive manual work, inconsistent brand communication, scattered product content, slow time-to-market, workflow inefficiencies, and the need for secure, centralized governance of digital assets and product information. [Source]
How does THRON PLATFORM improve productivity and efficiency?
THRON PLATFORM automates workflows, recovers up to 80% of time spent on manual tasks, and saves up to 3 months per user per year. It also consolidates tools, reducing IT budgets by 55%. [TEI Report]
What are some real-world success stories with THRON PLATFORM?
Customers like KitchenAid (Whirlpool) reduced image editing and publishing time by 66% and file replacement time by 99%. ACF Fiorentina improved video distribution performance, and Chervò accelerated integration with e-commerce channels. [Customer Stories]
Which industries are represented in THRON PLATFORM case studies?
Industries include fashion, sporting goods, beauty & pharma, manufacturing, interior design, retail, sports, ceramics, and e-commerce. Examples: Twinset (fashion), Dainese (sporting goods), Pettenon Cosmetics (beauty), Selle Royal Group (manufacturing), LAGO (interior design), Platum (retail/e-commerce), Fiorentina (sports), Atlas Concorde (ceramics). [Case Studies]
What feedback have customers given about the ease of use of THRON PLATFORM?
Customers highlight the platform's simplicity and automation. For example, a CMO at a manufacturing company noted that asset searches now take "two clicks," and a digital product manager in fashion praised the elimination of manual channel updates. [Marketing Solutions]
Implementation & Support
How long does it take to implement THRON PLATFORM?
THRON B2B Area can be activated in less than a week. Customers receive dedicated onboarding and training to ensure a smooth start, minimizing learning costs and timeframes. [Source]
What support services does THRON PLATFORM offer?
THRON provides technical assistance via a dedicated support team, a Customer Success Program for onboarding and training, and self-service resources such as guides, videos, and troubleshooting materials. [Services]
How can customers stay updated on THRON PLATFORM developments?
Customers can access monthly release notes to stay informed about the latest platform updates and improvements. [Release Notes]
What resources are available for troubleshooting and learning?
THRON offers a Help portal with guides, videos, and troubleshooting materials, as well as access to technical documentation and customer support. [Help Portal]
Competition & Comparison
How does THRON PLATFORM differ from other DAM and PIM solutions?
THRON PLATFORM uniquely combines DAM and PIM functionalities in a single platform, eliminating the need for costly integrations and reducing complexity. It also offers AI-powered automation, a single source of truth, omnichannel delivery, and a dedicated customer success program. [Source]
Why should a customer choose THRON PLATFORM over alternatives?
Customers should consider THRON PLATFORM for its unified DAM and PIM, automation capabilities, centralized repository, omnichannel optimization, and strong customer success support. These features help maximize productivity, reduce costs, and accelerate ROI. [Source]
What are the advantages of THRON PLATFORM for different user segments?
Marketing teams benefit from centralized content and automated workflows; e-commerce teams from improved user experience and faster time-to-market; operations from streamlined workflows; digital/CIO roles from seamless integration; and IT teams from a simplified, secure tech stack. [Source]
What specific features set THRON PLATFORM ahead of competitors?
THRON PLATFORM stands out with its unified DAM and PIM, AI-powered automation, single source of truth, omnichannel capability, and a customer success program that accelerates ROI. It also delivers measurable benefits such as 80% time recovery on manual tasks and up to 7,000 in financial benefit over three years (Forrester TEI). [TEI Report]